
Полная версия интервью. В бумажной газете и в .pdf опубликована сокращенная.

Допуск к архивной информации — одна из самых больших академических привилегий. Исследователь, который работает с источниками, уязвим многократно: материалы могут быть закрыты правообладателями, сотрудниками самого архива или управляющими структурами. Но даже если удается преодолеть препятствия, все равно остаются организационные проблемы, решение которых отнимает время, а успех неочевиден. Как наладить процесс сканирования и сохранения литературных архивов в оцифрованном виде и обеспечить неограниченный доступ к ним для исследователей и для всех желающих? Как хранить и обрабатывать данные? Как соединить разрозненные архивы? Здесь возникает множество технологических и юридических вопросов.

Елена Пенская, докт. филол. наук, ординарный профессор НИУ ВШЭ, руководитель электронного архива русской литературы «Автограф», продолжает цикл бесед на эти темы с известными учеными. Представляем вашему вниманию интервью с Игорем Пильщиковым, докт. филол. наук, проф. UCLA, вед. науч. сотр. ИМК МГУ и ТЛУ.
Предыдущие публикации: интервью с Дарьей Московской, заведующей отделом рукописей и заместителем директора Института мировой литературы РАН; рассказ о работе портала «Автограф»: «Время черновиков», «Три Михаила и четыре тысячи страниц».
— Для начала давайте поговорим о проектах, связанных с цифровыми архивами, цифровой текстологией, которые для вас важны.
— Я бы ограничил термин «цифровые архивы»: все-таки он подразумевает электронные версии традиционных архивохранилищ. А в более широком смысле продолжает употребляться понятие «электронная библиотека».
Я участвовал в создании нескольких электронных библиотек. Первой из них была «Русская виртуальная библиотека» (РВБ) [1], которую мы разрабатывали вместе с Евгением Горным и Владимиром Литвиновым. Она открылась 1 декабря 1999 года, и на старте в ней были представлены всего четыре издания: 10-томное собрание сочинений Пушкина, стихи Батюшкова, «Творения» Хлебникова и антология «Неофициальная поэзия». Все они делались по-разному: никаких стандартов не было, мы экспериментировали с подачей материала (воспроизводить или не воспроизводить структуру и пагинацию исходного печатного издания, иллюстрации и т. д.), с соотношением репродуцирования старой и добавления новой филологической информации (так, мы довольно быстро поняли, что в одном проекте практически невозможно совмещать библиотечную и текстологическую деятельность: либо мы воспроизводим существующее издание, либо делаем новое; гибриды же почти всегда неудачны). Однако с самого начала мы следовали базовому принципу: литератературные тексты даются с «эскортом» справочного аппарата — комментариев и сопроводительных статей. Это — минимальное условие научности библиотеки (для нашей дисциплины научность может быть приравнена к «филологичности»). Сейчас в РВБ представлены авторитетные издания трех десятков русских классиков XVIII–XX веков, а также несколько объемных антологий, включающих произведения еще четырех сотен авторов. Библиотекой пользуется от полумиллиона до двух миллионов посетителей в месяц, в среднем около миллиона, причем большинство посетителей — школьники и студенты. Поэтому недавно мы начали планомерно пополнять библиотеку произведениями школьной и университетской программы. В целом по посещаемости РВБ и раздел классики «Библиотеки Максима Мошкова» [2] стабильно занимают место в середине второй десятки литературных сайтов Рунета. Это и есть показатель популярности классического канона — не очень высокий, но стабильный, во многом поддерживаемый системой среднего и высшего образования. Уже много лет РВБ не имеет никакой финансовой поддержки, и это ставит под угрозу возможность дальнейшего развития проекта.
Вторым проектом стала Фундаментальная электронная библиотека русской литературы и фольклора (ФЭБ) [3]. Ее мы создавали совместно с Константином Вигурским и его лабораторией инфотехнологий в тесной кооперации с коллегами из Института мировой литературы РАН [4]. ФЭБ была открыта для пользователей 1 июля 2002 года, однако работа над ней как локальным (не сетевым) продуктом начались еще в середине 1990-х. Мы сразу сформулировали для себя различие между стратегиями двух библиотек: РВБ движется «вширь», ФЭБ — «вглубь». Авторов в ФЭБ меньше, но они представлены не одним, а несколькими авторитетными изданиями, а в «эскорт» входят важнейшие статьи и монографии об авторе, посвященные ему сериальные издания, библиографии произведений автора и работ о нем и другие релевантные материалы (например, музыкальные). Воспроизводятся все основные особенности исходных печатных изданий: структура, пагинации, номенклатура шрифтов. Издания, посвященные одному автору (в случае древнерусской литературы — произведению, в случае фольклора — жанру), образуют автономную информационную систему — структурированное «электронное научное издание» (ЭНИ) со своей системой поиска. В основе ФЭБ — десяток таких авторских ЭНИ (Пушкин, Грибоедов, Лермонтов, Гоголь, Лев Толстой, Маяковский…), а также специальные ЭНИ, в которых представлены академические истории русской литературы, литературные энциклопедии, словари русского литературного языка. К середине 2010-х годов стратегия воссоздания печатных изданий средствами глубокой разметки во многом исчерпала себя, поэтому мы «заморозили» проект: с 2016 года он не пополняется новыми публикациями. Однако ФЭБ не исчерпал себя как информационный ресурс: накопленная информация по-прежнему востребована профессионалами. Что такое ФЭБ в цифрах? Это полные тексты около 150 тыс. произведений 4,5 тыс. авторов (включая, разумеется, авторов комментариев, справочных и энциклопедических статей и т. д.), свыше 350 тыс. словарно-энциклопедических статей, около тысячи нотных текстов и фонограмм, тысячи факсимиле и иллюстраций. Посещаемость у ФЭБ была такой же, как у РВБ, но существенно снизилась за последние годы, когда ресурс перестал обновляться; те, кто остались, — это профессиональные пользователи по всему миру. Программное обеспечение ФЭБ также не обновляется; это значит, что в какой-то момент библиотека может просто перестать существовать.
В последние годы мы с коллегами из Института мировой культуры МГУ [5] — и снова с Вигурским и его командой — разработали информационную систему «Сравнительная поэтика и сравнительное литературоведение», СПСЛ [6]. Мы с Верой Полиловой уже рассказывали о ней на страницах «Троицкого варианта» чуть больше года назад — в декабре 2019 года, когда проект был открыт для пользователей [7]. Это информационная система, объединяющая в себе несколько подсистем. Одна из них организована как электронная библиотека, а вторая, связанная с ней, представляет собой корпус параллельных текстов. Есть и другие подсистемы: «Энциклопедия» (со сведениями об авторах) и «Тезаурус» (пояснение научных терминов) — и система поиска: полнотекстового лексического и атрибутного, по библиографическим и стиховедческим параметрам.
— Как бы вы прокомментировали динамику развития цифровых библиотек и цифровых архивов? Их соотношение? Как эволюционируют идеи и практики?
— В самых общих чертах мне это видится так. Сначала в девяностые годы появляются первые энтузиасты; первый образец электронной библиотеки дал «Проект Гутенберг» [8] — большая коллекция электронных текстов в очень простых форматах, без специального внимания к текстологии, без расширенного поиска. Ее аналогом в России стала «Библиотека Мошкова». Главный пафос первого этапа состоял в том, чтобы изготовить хоть какие-то цифровые тексты и начать ими пользоваться. Так сказать, не до жиру. Пусть сначала появятся тексты с ошибками, потом мы начнем их исправлять. Была большая надежда на пользовательское участие, на то, что пользователи будут интерактивно корректировать неточности. Хотя такие попытки периодически предпринимаются до сих пор (да и всякая библиотека имеет обратную связь — получает сведения об ошибках), но все-таки такое сотворчество производителей и пользователей не стало главным направлением развития, т. е. по большому счету не состоялось. Хотя, может быть, еще состоится в будущем, я не знаю.
Второй этап — профессионализация ресурсов. В какой-то момент стало понятно, что нужно оцифровывать не всё подряд и абы как, а делать ресурсы по интересам. Именно тогда и появляются обе библиотеки, которые я упомянул: РВБ и ФЭБ. И одновременно возникает новая установка у крупных традиционных библиотек — делать электронные копии своих печатных изданий и создавать коллекцию цифровых копий, которая превращается в электронную библиотеку.
Одной из первых, если не самой первой, на этот путь ступила Национальная библиотека Франции (НБФ), которая сформировала электронную коллекцию «Gallica» [9]. Новшество заключалось в том, что для оцифрованных книг использовались библиографические описания, сделанные в самой библиотеке. Каталог НБФ очень хорош, он существовал в печатном виде, а затем был трансформирован в базу данных, представлен в виде интернет-каталога, и дальше эти описания послужили идентификаторами для книг в электронной коллекции [10]. Коллекция существует и сама по себе (как электронная библиотека), и как приложение к каталогу — можно из каталога выйти не только на список книг в разных отделах НБФ, но и на их электронные копии.
Этот путь оказался очень продуктивным, но, естественно, такое может позволить себе только большая национальная библиотека. В России его выбрали и Российская национальная библиотека в Петербурге [11], и Российская государственная библиотека в Москве [12]. Однако у них есть по меньшей мере один минус, как мне кажется: электронные цифровые коллекции в обеих библиотеках работают так же, как «Gallica», то есть как приложение к каталогу (и это очень хорошо), но не имеют собственного развитого интерфейса. В результате многие пользователи даже не знают о том, что в этих библиотеках есть крупные электронные ресурсы, не знают, что очень много книг, журналов, газет XIX и начала XX века оцифровано — и они находятся в свободном доступе. Внешними поисковыми системами (Google, «Яндекс») эти коллекции не индексируются.
А сейчас, как мне кажется, идет этап новой профессионализации и спецификации, когда разрабатываются новые технологические средства или новые принципы построения электронных продуктов. Такие продукты должны быть настроены на эффективную работу с определенной областью знания и решать определенные профессиональные, а не только общепользовательские задачи.
Например, при подготовке корпуса параллельных текстов СПСЛ, в отличие от лингвистических корпусов, которые прежде всего построчно и пословно соотносят именно пару текстов — оригинал и перевод, мы занимаемся историей поэтических переводов, для которых важна множественность. Обычно это не два параллельных текста, а больше: бывают переводы-посредники, переводы с переводов и т. д., они выстраиваются в цепочки, и эти цепочки сложно переплетаются, т. е. их уже нельзя назвать параллельными в узком смысле слова. И нам пришло в голову, что эти связи было бы удобно представлять в виде графа, пучка переводов, связанных определенными отношениями, — кластера, внутри которого тексты попарно параллельны. В упомянутой публикации в «Троицком варианте» [7] мы приводили пример — русские переводы 279-го сонета Петрарки, из которых шесть сделаны с итальянского оригинала, а один — с немецкого перевода-посредника. Вот аналогичный пример, чуть попроще, но и нагляднее, — романс из «Дон Кихота» Сервантеса, который переводчица начала XX века переводит с испанского, а основоположник русского поэтического перевода Жуковский — с французского перевода Флориана:

| Marinero soy de amor Y en su piélago profundo Navego sin esperanza De llegar a puerto alguno.Siguiendo voy a una estrella Que desde lejos descubro, Más bella y resplandeciente Que cuantas vió Palinuro.Yo no sé adonde me guía, Y así navego confuso, El alma a mirarla atenta, Cuidadosa y con descuido.Recatos impertinentes, Honestidad contra el uso, Son nubes que me la encubren Cuando más verla procuro.¡Oh clara y luciente estrella En cuya lumbre me apuro! Al punto que te me encubras, Será de mi muerte el punto. Мигель де Сервантес (1605) |
По любви волнам безбрежным Мореход любви плыву я, Но не светит мне надежда, Что могу войти я в гавань.Путь держу я за звездою, Что мне издали сияет — Лучезарней и прекрасней, Чем все звезды Палинуро.Приведет куда не знаю Та звезда — плыву в смятеньи, Беззаботный, полн заботы, Устремясь к ней всей душою,— — — —О звезда, твоим сияньем Лишь одним живу, дышу я, И в тот миг, как ты погаснешь, В тот же миг умру и я. Сервантес в пер. Марии Ватсон (1905) |
| Dans une barque légère, Hardi, tremblant, tour-à-tour, J’errois sur la mer d’amour, Ne sachant où trouver terre.Un astre, mon seul espoir, Me guidoit dans ma carrière, Je voguois à sa lumière, Je ne voulois que le voir.— — — —Hélas! depuis qu’un nuage Couvre cet astre si beau, Les cieux n’ont plus de flambeau, Mon cœur n’a plus de courage.Astre charmant, reparois, Prend pitié de mon jeune âge, Et sauve-moi du naufrage En ne me quittant jamais. Сервантес в пер. Флориана (1798) |
Ладьею легкой управляя, Блуждал я по морю любви. То страх, то смелость ощущая. Нигде не открывал земли!Одно прелестное светило Сияло на пути моем; Оно моей надеждой было, Я видел путь и плыл по нем.— — — —Но ах! с тех пор, как туча скрыла Его сиянье от меня, С тех пор на небе нет светила, С тех пор лишен надежды я!Взойди опять, звезда златая, И путь мой снова озаряй, Меня от бури сохраняя, Вовек, вовек не покидай! Сервантес / Флориан в пер. В. Жуковского (1804) |
Тут есть некий парадокс: даже по числу катренов и по рифмам видно, что Жуковский передает французский текст, не заглядывая в испанский; но при этом он прекрасно понимает, что переводит великий роман Сервантеса (Жуковский перевел весь роман, а не только стихотворные вставки). Прямых соответствий между текстами Жуковского и Сервантеса нет, но есть соответствия между русским и французским текстом, с одной стороны, и французским и испанским, с другой. С первого взгляда видно, что непривычную для французской и русской традиций ассонансную рифмовку испанского текста Флориан (и вслед за ним Жуковский) передают точными рифмами, а Мария Ватсон — нерифмованными окончаниями. Если бы перевод Ватсон опирался не только на испанский оригинал, но и на перевод Жуковского, на схеме понадобилась бы еще одна стрелка, и наш граф бы замкнулся. Но оснований предполагать, что текст Жуковского выступил в роли перевода-посредника, у нас нет: хотя в позднем переводе тоже пропущено одно четверостишие, это не то же самое четверостишие, которое пропущено у Флориана и Жуковского.
Сейчас в публичной версии системы полностью приведены только два процитированных произведения из четырех, а два других, помеченных на схеме значком Ø, представлены только библиографическими и стиховедческими метаданными. Однако в тестовой версии — препринте, в котором готовится и «обкатывается» система, — эти тексты уже есть. А если бы еще не было, значки Ø служили бы для нас сигналом: нужно найти издания, в которых напечатаны эти произведения, и оцифровать их.
Установить соответствия между фрагментами в таком пучке уже гораздо сложнее, хотя эту задачу мы тоже перед собой ставим. Даже из приведенного выше примера видно, насколько полезна синхронизация фрагментов. Однако нередко в переводах лирики соответствия между фрагментами неочевидны: перевод часто не эквилинеарен, в нем действуют компенсаторные механизмы (отсутствие эквивалента в одном месте или на одном уровне компенсируется наличием эквивалента на другом уровне или в другом месте), может переводиться не смысл текста, а звук и/или ритм и, наконец, какие-то фрагменты могут варьировать не оригинал, а перевод-посредник. Вот, например, сонет Бодлера в переводе Вячеслава Иванова:

В первом полустишии сочетание глагола с наречием (j’ai longtemps habité «я долго жил») передано сочетанием существительного с местоимением (моей обителью). Семантика передана приблизительно, зато звук воспроизведен очень близко: l[ɔ̃tã] (h)abité ≈ [а]бите+ль. Иванов не воспользовался возможностью передать заимствованным портики первое рифмующее слово сонета (portiques), но зато он воспроизвел саму рифму на -[ikə] (с произносимым в стихе «e немым»): «portiques : basaltiques : mystique : musique» ≈ «великий : блики : лики : музы́ки». Архаическое музы́ки семантически, ритмически и фонетически соответствует французскому musique, но в переводе это слово завершает 8-й стих, а не 7-й, поскольку последовательность мужских и женских рифм в переводе инвертирована: катренам ЖммЖ у Бодлера соответствуют катрены мЖЖм у Иванова. Соответствия оборачиваются несоответствиями, и наоборот.
Поэтому мы подошли к задаче построения параллельного корпуса с другой стороны. Лингвисты изучают параллельные тексты с установленными соответствиями между фрагментами, наращивая эти параллелизмы, а мы, литературоведы-компаративисты, изучаем кластер, репрезентирующий множественность переводов одного текста. Вот такими разработками специальных средств для специальных задач, по-видимому, и характеризуется нынешний этап развития электронных библиотек.
Другая характерная для нынешнего этапа черта — семантизация гипертекста. Как известно, гипертекст — основа Интернета. Но когда мы переходим по какой-нибудь гиперссылке, то, строго говоря, не всегда знаем, куда именно она ведет. Идея «семантической сети» заключается в том, чтобы придать связям конкретное значение. Например, в СПСЛ эксплицированы связи между текстами, т. е. обозначена либо связь оригинала с переводом, либо перевода — с переводом-посредником, либо оригинала — с его источником (например, прозаическим). Кроме того, для нас принципиально важны связи между текстом в корпусе и изданиями в библиотеке. В системе выделены довольно простые семантические категории. Ссылки от текста в корпусе идут либо к изданию этого текста, либо к комментарию, либо к исследованию об этом тексте, и наоборот. Получается своеобразный аналог развивающейся аннотированной библиографии.
При таком подходе весь гипертекст действительно оказывается насыщен смыслом. Судя по недавнему анонсу, на похожих принципах строится и новый проект НИУ ВШЭ «Осип Мандельштам Digital» [13]. Он стартовал лишь недавно, создатели обещают в ближайшем будущем открыть его для пользователей.
— Каков портрет сегодняшнего пользователя таких проектов?
— В значительной степени работа по созданию библиотек проходит не на глазах у публики, и публика ею не очень интересуется. Кроме того, основная масса пользователей Интернета не занимается поиском профессионально — это не филологи, которые уже научились работать с традиционными библиотеками и архивами, а теперь учатся работать с электронными: это школьники, студенты и «просто читатели». Они щелкают по первым ссылкам, которые выдает поисковик, и тем удовлетворяются. Как правило, они даже не знают, что они читают, откуда и куда приходят, что это за библиотека.
Такова оборотная сторона демократизации информационного поиска. С одной стороны, вся информация становится доступной «в один клик», с другой стороны — пользователь теряет навык критической работы с информацией, отвыкает проверять ее и понимать, насколько авторитетен тот или иной источник, потому что представления о том, что это за источники, у массового пользователя Интернета нет. Зато есть смешные мифы о том, что «в Сети всё есть», что якобы любая книга доступна в Интернете. Это, конечно, далеко не так.
— Насколько студенты владеют навыками работы с электронными библиотеками?
— Многие студенты умеют искать тексты в Интернете, умеют давать ссылки на электронные ресурсы, но довольно часто они, например, дают ссылки на разные тексты, скажем, Пушкина по разным изданиям. Конечно, пушкинисты тоже не пользуются одним-единственным изданием, но они сознательно отбирают одно или несколько и цитируют по какому-то авторитетному изданию или по тому, которое удобно для их целей, а к другим обращаются, если основное издание в каком-то отношении неудовлетворительно. Кроме того, студенты часто произвольно цитируют одно и то же произведение то по одному, то по другому изданию. Это результат отсутствия базовых текстологических знаний, наивное представление, что существует только один текст «Евгения Онегина» или «Войны и мира». Между тем Пушкин печатал «Онегина» трижды (сперва поглавно, а затем отдельными изданиями в 1833 и 1837 годах). Принятая ныне критическая редакция-реконструкция, во-первых, не является единственно возможной, а во-вторых, не соответствует ни одному из этих изданий, а располагает текст, более-менее соответствующий тексту 1833 года (где, например, посвящение Плетнёву перенесено в авторские «Примечания к Евгению Онегину»), в соответствии с композицией издания 1837 года (которое открывается посвящением Плетнёву). Ряд строк, известных нам из изданий советского времени, перенесен в критическую редакцию из рукописей, и многие решения не бесспорны. Так что на вопрос о том, как правильно читается та или иная строка «Евгения Онегина», нередко можно дать два, а то и три разных ответа. Такую ситуацию можно называть «ситуацией текстологической неопределенности». Наличие в тексте таких фрагментов — не исключение, а правило. Даже у такой общеизвестной строчки Пушкина, как «Звезда пленительного счастья» (из послания Чаадаеву 1818 года), в действительности есть два равноправных варианта: «Звезда пленительного счастья» и «Заря пленительного счастья». Автографы стихотворения до нас не дошли, а в списках с примерно равной частотой встречаются оба варианта. До 1930-х годов предпочтение отдавали второму (именно его цитирует, например, Герцен в «Былом и думах»), а вариант со «звездой» утвердился как основной только в академическом издании 1937 года.

Толстой несколько раз печатал «Войну и мир», и тоже каждый раз по-разному. (См. лекцию Ильи Бендерского.) Если взять в расчет только отдельные издания, мы увидим, что автор так и не выбрал окончательной композиции для своего романа (не говоря уже об окончательном чтении отдельных фраз этого огромного произведения). Два первых отдельных издания 1868–1869 годов — шеститомные, а привычная нам разбивка на четыре тома появилась только в третьем издании 1873 года, причем Толстой колебался, «как лучше: с старым разделением или по-новому». Далее, в третьем издании из текста романа были изъяты все историофсофские отступления и философская часть эпилога — они были напечатаны отдельно под заглавием «Статьи о 1812 годе». Наконец, Толстой перевел на русский многостраничные французские диалоги (иногда исправляя и самый их текст), таким образом лишив свое творение одной из ярчайших стилистических особенностей: роман о войне русских с французами наполнен французскими репликами, но по-французски говорят не французы, а европеизированная русская аристократия, владеющая французским лучше, чем русским. Последнее издание, которым руководил сам Толстой, — четвертое, 1880 года — по композиции и составу повторяет третье. Однако тексты, которые сегодня попадают нам в руки, не соответствуют ни одному из этих изданий.
Основой ныне принятого текста стало пятое издание романа, осуществленное Софьей Андреевной Толстой в 1886 году: она вернула в четырехтомную композицию первоначальный текст. А в шестом издании, вышедшем под ее наблюдением в том же 1886 году, французские тексты вновь заменены русскими, но историософские главы сохранены. С 1887 по 1930 год перепечатывался текст пятого издания 1886 года. Позднейшие публикации основываются на тексте второго издания 1869 года, однако восстанавливают толстовскую стилистическую правку 1873 года. Это можно сделать разными способами, и даже в двух тиражах томов «Войны и мира» 1930-х годов из юбилейного 90-томного Полного собрания сочинений Толстого текст разный. А в 1961–1963 годах в составе 20-томного собрания сочинений вышло новое издание романа, для которого была проведена фронтальная сверка всех печатных и рукописных редакций текста, и в него было внесено более двух тысяч локальных поправок. Прочие издания опираются на одно из авторитетных, причем с разными вариациями. Какие, например, давать переводы французского текста — редакторские или толстовские? Наверное, толстовские, но ведь они не всегда соответствуют французским фразам, поскольку русский текст Толстой менял, а французский — нет.
Когда эти тексты переходят в Сеть, проблема усугубляется, потому что одно и то же издание может быть на нескольких сайтах; иногда они там отождествлены как электронные версии одного и того же печатного издания, а иногда нет; иногда на разных сайтах воспроизведены разные издания, нередко с произвольными искажениями. При этом студент легко может дать три разных ссылки на одно и то же произведение Пушкина или Толстого то из библиотеки Мошкова, то из РВБ, то вообще непонятно с какого сайта — и не видит в этом проблемы. Культура идентификации источника утрачивается.
— Как наладить обучение в этой области?
— Конечно, желательно разработать отдельный предмет. Есть разные дисциплины, которые гуманитарии привыкли считать вспомогательными: текстология, библиография, теперь к ним же относят интернет-поиск. Можно включить их в общую зонтичную дисциплину и назвать ее, например, «культура информационного поиска». Необходимо учиться искать информацию не только в Интернете и в электронных каталогах, но и в традиционных библиотеках. Кроме того, нужны элементы архивоведения. Даже если в куррикулуме, избранном студентами, нет курса библиографии, им всё равно придется оформлять библиографию к курсовой и другим работам.
— А теперь я бы хотела поговорить о цифровизации литературных архивов, черновиков и записных книжек. Насколько это важно, на ваш взгляд? Все-таки массовый пользователь работает с опубликованными текстами.
— В Интернете появляется всё больше архивных материалов. Речь идет как об описательной части архивов, т. е. описях фондов со списками единиц хранения, так и об электронных копиях самих документов. Может быть, они нужны не очень широкому кругу читателей, но специалисты живут и работают в разных точках планеты и не всегда могут добраться до архивных документов, которые к тому же могут быть разрознены.
Рукопись — вещь хрупкая, и если ею слишком часто пользоваться, она быстрее изнашивается. Поэтому до эпохи Интернета изготовляли фильмокопии, а еще раньше возникла культура факсимиле. Но фильмокопии не дают достаточно высокого качества изображения, а печатных факсимиле много не сделаешь — это дорогостоящая вещь.
Относительно недавно появились прекрасные печатные факсимиле пушкинских автографов, сделанные в Пушкинском Доме: восемь томов рабочих тетрадей Пушкина с комментариями (1995–1997) и три тома болдинских рукописей (2013). Ясно, что с такими бумажными факсимиле удобно работать, потому что в них, в отличие от фильмокопий и фотокопий пушкинских рукописей, сделанных в 1950-е годы, воспроизведен цвет, у них высокое качество изображения. Цвет чернил помогает понять, одновременно или разновременно были сделаны записи и к какому из двух-трех слоев относятся отдельно выписанные слова. Кроме того, эти факсимиле фиксируют текущее состояние манускрипта. Пройдет сто лет, и, возможно, в этих рукописях что-то исчезнет — ведь карандаш стирается, чернила выцветают.
Ясно, что с электронными копиями плюсы только прибавляются. Во-первых, электронная копия доступна пользователю вне зависимости от того, где пользователь находится. А сейчас, когда мы оказались заперты по домам из-за пандемии, еще более очевидной стала необходимость доступа к такого рода информации из любой точки планеты. Во-вторых, электронную копию можно увеличивать; можно фокусироваться на совсем микроскопических деталях текста, которые раньше удавалось рассмотреть только с лупой, а то и с лупой не рассмотришь. В-третьих, существуют способы специального сканирования, позволяющего проводить спектрографический анализ. С его помощью в рукописи можно увидеть то, чего невооруженным глазом не видно. Так, текстологи из Пушкинского Дома, работающие над созданием объединенного цифрового архива Достоевского [14] и спектрографией его рукописей, соотнесли типы чернил, использованных Достоевским для написания всех имеющихся в автографах дат, с типами чернил в документальных и творческих рукописях. Особо ценный материал дают письма, позволяющие связать место и дату, зафиксированные рукой самого писателя, с типом чернил, использованном в данном письме. База данных таких соответствий позволила, например, датировать записи из «Сибирской тетради» Достоевского, относительно которых у текстологов не было единого мнения и которые невозможно было датировать по содержанию или наблюдаемым невооруженным глазом палеографическим признакам [15].
Наконец, объединенные электронные архивы решают еще одну очень важную проблему. Есть масса случаев, когда произведения одного автора разбросаны по разным архивам страны или всего мира. Поэтому необходимость в таких проектах, как создание объединенного архива Мандельштама [16] или объединенного архива Вячеслава Иванова [17], мотивирована тем, что документы рассредоточены: рукописи Мандельштама частично хранятся в Принстонском университете, частично в России; часть рукописей Вячеслава Иванова находится в России, а часть — в Риме, где он жил в эмиграции. Так что ближайшее будущее — за объединенными цифровыми архивами, тематическими или посвященными конкретной персоне.
— Сейчас немало говорят о расшифровке рукописей машинным способом. Насколько она налажена и необходима?
— Один из аргументов пользу дигитализации рукописей состоит в том, что большинство их не были и не будут переведены в печатную форму. Посмотрите картотеку архивных материалов по любой теме: вы увидите, что 70–80% релевантных для темы рукописей не напечатаны, а в лучшем случае упомянуты или кратко процитированы. И это вполне обычное соотношение при переводе текстов на новые носители информации. Та же ситуация с печатными изданиями: из 130 млн условных книг (по подсчету Google) оцифровано около 40 млн, и то в основном благодаря нескольким мегапроектам (Google Books, Gallica).
Далее: в отличие от книг, «читать глазами» рукопись могут только специалисты по почерку данной эпохи, а иногда даже данного автора. Поэтому без distant reading рукописи останутся «великим непрочтенным» навсегда. Следовательно, нужно научиться читать их автоматически, а не просто представлять в электронной форме результаты традиционных методов чтения. Это — «движение вширь». Что же касается «движения вглубь», то по мере того, как распознавание рукописного текста будет становится всё более sophisticated, есть надежда, что появится возможность уточнить традиционные прочтения классических текстов, избавиться от тех сотен тысяч «НРЗБ», которые не удалось расшифровать даже лучшим текстологам. Уже сейчас многие программы оптического распознавания текста (optical character recognition — OCR) способны «прочесть» не только печатный, но и рукописный текст. Опция распознавания рукописного текста на многих языках включена в последние версии ABBYY FineReader. Этот российский продукт — не только отечественный, но и глобальный флагман в мире OCR. Так, еще в 2014 году ABBYY объявила о добавлении в FineReader опции распознавания медицинского почерка.
Разумеется, понадобится ручная редактура (универсальный принцип: «после сборки ручная доводка») — но ведь она зависит от нужной нам степени точности. Если наша задача — выбрать из корпуса в 100 тыс. рукописей все, где идет речь о продаже овец, или отделить рифмованные стихи от прозы, мы можем пренебречь множеством ошибок распознавания (предлогов, цифр, редких терминов).
— Понятно, что польза от цифровых рукописных архивов имеется. Но ведь эти растровые изображения — информационный хаос. Что с ними делать? Расшифровывать всё и создавать семантическую разметку? Какие исследовательские задачи это позволит решить? И в чем принципиальное отличие задач, поставленных для рукописных Big Data?
— Несомненно, возникнут специфические задачи, связанные с особенностями манускрипта как носителя информации.
Во-первых, это почерки: они имеют гораздо большее разнообразие и значимость, чем гарнитуры. Да, есть периоды, когда выбор шрифтового оформления культурно значим: например, выбор фрактуры («готики») или антиквы для немецкого языка в XIX–XX веках или выбор церковной либо гражданской печати в петровскую и послепетровскую эпоху в России. Но с почерками таких ситуаций гораздо больше. Во многие периоды различались почерки современные и архаические — вспомним, например, характерное для русского XVIII века написание буквы «в» в виде «#», которое в первой четверти XIX века быстро выходит из употребления. Были периоды, когда радикально различались женские и мужские почерки. Так, в Англии от аннинской до викторианской эпохи девочек учили писать более беглым и заостренным курсивным почерком, а мальчиков — более солидным и скругленным.
Во-вторых, остаются релевантными все другие палеографические признаки: сорт бумаги, водяные знаки и прочие, помогающие датировать рукопись. Какие-то задачи будут решаться автоматически или полуавтоматически (например, каталог почерков и начертаний отдельных символов), какие-то потребуют решения проблемы метаданных (например, создание унифицированных палеографических и археографических описаний; думаю, не все представляют себе, насколько это сложная и трудноразрешимая задача). Но всё это в конечном счете позволит ввести в научный и образовательный оборот миллионы рукописей, которые иначе останутся непрочтенными или, в лучшем случае, прочитанными одним-двумя исследователями. Между тем работы по оцифровке рукописей едва только начались. Я уже говорил о цифровых архивах Достоевского, Мандельштама и Вячеслава Иванова и ситуации с рукописями Пушкина. Больше у нас, кажется, ничего не оцифровано хоть с какой-то степенью полноты, только отдельные страницы или документы (я говорю о русской классической литературе). Только представьте себе: у нас нет оцифрованных рукописей Ломоносова, Державина, Жуковского, Батюшкова, Лермонтова, Гоголя, Тютчева, Некрасова, Фета, Льва Толстого, Чехова, Горького, Брюсова, Блока, Маяковского, Хлебникова, Цветаевой, Ахматовой, Ходасевича, Замятина, Зощенко, Бабеля, Пастернака, Солженицына, Бродского. Список можно продолжать до бесконечности.
— Как быть с теми правовыми вопросами, которые неизбежно возникают, когда открывается широкий доступ к документам?
— Существующая система копирайта принципиально устарела в момент появления Интернета, а сейчас, когда число текстов, распространяемых в электронной среде, существенно превзошло число всех прочих текстов, она устарела катастрофически, и предпринимаются серьезные попытки ее изменить. Я имею в виду такие инициативы, как директива Европарламента и Совета Европы № 1290/2013 о том, что все научные публикации, которые спонсируются грантами рамочной научной программы Евросоюза «Горизонт 2020» (2014–2020), должны быть опубликованы в свободном доступе — и для оплаты (издательствам) бесплатного (для пользователя) доступа выделяются целевые средства1. Но это пока частичные решения, а менять всё нужно радикально, ведь в принципе изменились соотношения между оригиналом и копией, между чтением и копированием, так что существующая система — просто бревно на пути прогресса. 1–2% коммерчески ориентированных авторов, возможно, и выигрывают от этого архаического распорядка, а все остальные авторы и читатели, наоборот, с трудом друг друга находят из-за имеющихся ограничений.
Как ни парадоксально, но есть один хороший пример влияния пандемии на электронный доступ — это временный доступ в цифровые собрания, который сейчас разрешен благодаря нынешней ужасной ситуации. В частности, такой доступ открывает большая электронная коллекция Hathi Trust [19]. Американские университетские библиотеки, которые предоставили Google свои фонды для оцифровки в Google Books, сохранили право на собственные электронные копии, и они хранятся в Hathi Trust. Эту коллекцию можно считать полноценной электронной библиотекой; в ней есть профессионально составленный каталог, все издания корректно библиографически идентифицированы. Доступ к ним не полностью свободен: полнофункционально коллекция доступна только для пользователей с университетским доступом. Вы можете работать со своего рабочего места, можете из дома, но для полноценного пользования коллекцией нужно быть аффилированным с университетом — участником консорциума. В этой электронной библиотеке можно знакомиться с книгами, находящимися в общественном доступе. Сейчас примерно по 1925 году проходит граница. Можно ожидать, что книги, вышедшие из печати раньше, будут, за какими-то редкими исключениями, предоставлены для свободного копирования.
А по отношению к более поздним изданиям Hathi Trust ведет себя даже жестче, чем Google Books. По результатам поиска Hathi Trust показывает только число вхождений и номера страниц, но не дает цитат в виде snippet view, как Google Books; и там нет отдельных книг для частичного просмотра, как в Google Books. Но вот сейчас множество книг, изданных с 1920-х по 1980-е годы, открыто для временного доступа, их можно получить на ограниченное время — как в библиотеке. Так же устроено еще несколько других цифровых хранилищ, которые намеренно начинают работать по модели традиционных библиотек, выдавая один экземпляр книги на время и без возможности копирования всего издания. И вот все убедились, что система взаимоотношений между автором, издателем и читателем за прошедший год не рухнула оттого, что был предоставлен доступ к десяткам тысячам малоспрашиваемых книг, которыми интересуются ученые: они всё равно не публикуются заново и даже у букинистов не всегда продаются. Остается только надеяться, что этот опыт будет как-то учтен, после того как пандемия закончится.
— Как, с вашей точки зрения, можно сбалансировать внутренние ведомственные интересы архивов и интересы исследователей?
— Научный поиск имеет общекультурное, общечеловеческое значение, поэтому ограничивать его ведомственными интересами — это в принципе неправильно. Возникает вопрос, в чем заключаются интересы архива, может ли держатель информации ограничивать доступ к информации. Если для этого существуют экономические причины, например если архивам выгоднее ограничивать доступ, чтобы делать его платным, то этот вопрос должен решаться политическим или экономическим путем. То есть мы должны найти механизмы компенсации. Во многих архивах и библиотеках мира копирование по пользовательскому запросу может быть бесплатным, если речь идет об ограниченном объеме — до 250 страниц, как в Колумбийском университете [20], или до 100 страниц, как в Гарвардском [21]. Выгода в этом случае двоякая: ведь если делается копия для пользователя, она остается в библиотеке. Уже оцифрованные материалы доступны пользователям бесплатно, один из многочисленных примеров — тот же Гарвард [22]. Нужно поощрять более разумный подход, нежели просто продажа злосчастному исследователю копии каждой странички по кусочкам. А как финансировать этот процесс, компенсировать отсутствие непосредственного дохода (не очень кстати, большого) — отдельный вопрос.
К сожалению, иногда — особенно в России — приходится сталкиваться с консервативностью архивных работников, которые говорят исследователям: вот, тридцать лет назад все приходили и переписывали документы авторучкой, а теперь вы сидите и переписывайте. И не потому что это вредно для источника, ведь есть уже много безвредных способов копирования, таких как холодное сканирование или фотография без вспышки со специальным освещением; не обязательно полностью раскрывать переплеты. Все эти проблемы технически решаются. По-моему, очевидно, что это ненужные ограничения. Это охранительная позиция. Из-за того что у меня нет копий, по которым я могу перепроверить свои выписки, я снова иду в архив, а это бессмысленная трата и моего времени как исследователя, и времени архивиста, который, вместо того чтобы в десятый раз выдавать мне одну и ту же рукопись, мог бы заняться другими делами. Это, наконец, вредит и самой рукописи, которую лишний раз поднимают в зал и возвращают на место. Поэтому библиотеки и архивы должны быть заинтересованы в том, чтобы делались цифровые копии, и в том, чтобы они по возможности заменяли бумажные оригиналы.
Наконец, очень вредна отчетно-бюрократическая погоня за посещаемостью, ложное или, по крайней мере, одностороннее представление о том, что посещаемость и число читателей — это якобы главный признак эффективности библиотеки. Нет, библиотека и архив — это прежде всего хранение. А как сделать так, чтобы снять антиномию хранения и пользования? Конечно, делать высококачественные копии и предоставлять доступ к этим копиям, не связанным с физическим местонахождением библиотеки и архива. Для этого электронные копии и Интернет дают идеальную возможность.
— Есть особые типы закрытости, когда, например, сотрудники архива выполняют какой-то заказ издательства и под этим предлогом доступ кому-либо извне закрывается. Насколько такое действие легитимно?
— Это вопрос к юристам. В советское и постсоветское время в ведомственных архивах, например, давался приоритет работникам соответствующих ведомственных институтов для работы с бумагами этого архива. Правомерность таких ограничений для меня сомнительна. С другой стороны, существуют ограничения во времени, ведь у каждого свой план. Но неужели оттого, что я пришел на пять минут раньше, у меня появляются какие-то юридические права на ту или иную рукопись? Мне это совершенно непонятно.
Как сказано в одной юмореске Жванецкого, «что охраняем, то и имеем; ничего не охраняем — ничего не имеем». Исследователь, получивший доступ к рукописи, иногда начинает «охранять» ее от «посягательств» других исследователей. Начинаются мелкие распри, которые очень вредят делу. Ведь с точки зрения универсального процесса публикации и функционирования информации ситуация, когда два человека хотят опубликовать один и тот же текст, очень редка. Главная проблема отнюдь не в этом, а в том, что огромное количество текстов не публикуется вовсе, т. е. абсолютное (подчеркиваю: абсолютное) большинство текстов никогда не увидит свет. По сравнению с этим «жерлом вечности» вопрос о праве на первую публикацию низводится до частного вопроса о личных амбициях отдельного исследователя.
— Теперь — к цифровой текстологии. Расскажите, как вы работаете? И чем цифровая отличается от обычной? Проецируются ли исследовательские задачи на цифровые архивы?
— Это целый комплекс вопросов. Главная, фундаментальная проблема возникла с самого начала и не разрешена, по-видимому, до сих пор. Заключается она в том, что невозможно с одного носителя перенести информацию на другой так, чтобы всё было совершенно адекватно воспроизведено. Что-то важное обязательно теряется, что-то, наоборот, приобретается. Это как при переводе с языка на язык.
На первых этапах, в самом начале 1990-х годов, было много проблем со шрифтами; было трудно даже совместить в одном документе латиницу с диакритикой и кириллицу. Когда появился юникод, эти проблемы удалось решить. Но до сих пор существуют разные небанальные задачи, которые в электронном издании решаются иначе по сравнению с печатным. Например, с точки зрения алфавитного состава латиницы готический шрифт (фрактура) и более привычный для нас шрифт типа «антиква» — это одни и те же символы (буквы, коды), но в разных гарнитурах. Значит, если мы не вводим в цифровую систему обязательную спецификацию гарнитуры, то мы это различие теряем. А если мы ее вводим, то доступ к нашему документу усложняется технически.
Технологии меняются, а нестандартные шрифтовые решения и средства их реализации, сделанные «на коленке», быстро устаревают, потому что следующий формат уже не учитывает всех этих шайбочек, привязанных веревочками, и вся эта самодеятельность просто пропадает. Универсальный, унифицированный процесс тоже не дает всех желаемых результатов. В юникоде всё время появляются новые символы, но не все они представлены в каждом шрифте, и, опять же, невозможно всю человеческую графику вместить даже в огромную таблицу. Есть отдельные символы разных языков, которые по той или иной причине в юникоде отсутствуют, и возникает вопрос, как их воспроизводить.
На следующей стадии развития Интернета, после того как «плоский» текст перестал быть интересен, воспроизведение печатных текстов и создание их аналогов достигалось с помощью глубокой разметки. Такая разметка бывает двух типов: логическая и ориентированная на определенную визуализацию текста (не считая специальной разметки, например лингвистической или стиховедческой). Иногда две эти функции разметки текста дополняют друг друга, иногда совпадают, иногда вступают в противоречие. Так или иначе, стало возможным воспроизводить сложные тексты на интернет-странице в виде, близком к печатному изданию. Но трудозатраты огромны, и всё равно все тонкости не воспроизведешь.
Можно поставить вопрос иначе: а зачем воспроизводить символы, если мы можем дать изображения? Но минус картинки в том, что невозможно скопировать фрагмент текста, невозможно наладить поиск. Дихотомия «текст – изображение» долгое время казалась неразрешимой, но в начале нынешнего века возник новый тренд, который сейчас побеждает. Пользователю представляется двухслойный документ, который содержит верхний слой — собственно изображение — и под ним текстовый слой; при этом документ однозначно соотносит эти слои между собой.
Вторая группа проблем — подача текста. Книжная текстология была ограничена тем, что, во-первых, в издании мало места, а во-вторых, пространство издания — двухмерное и ограниченное. Где разместить альтернативный текст (варианты) и метатекст (комментарии)? Как правило, альтернативный текст никогда не воспроизводился полностью. Теперь эти ограничения уходят.
— А как обстоит дело с рукописями?
— В печатном издании практически невозможно соотнести рукопись и ее расшифровку. Даже вопрос о том, как подавать саму расшифровку, не решается однозначно.
В этом отношении русская текстология в свое время разделилась на два направления. В конце XIX века, в позитивистскую эпоху, когда исследователям стало интересно читать не только канонические тексты, но и всё написанное автором, когда всё стало восприниматься как документ эпохи, начали появляться издания, в которых воспроизводятся автографы и авторитетные копии. Их передавали с помощью транскрипций, когда текст размещался на печатном листе так же, как он располагался в автографе. Так сделано первое, дореволюционное академическое издание сочинений Пушкина. Видно, что именно было исправлено, зачеркнуто или восстановлено.
Но, во-первых, это соответствие было не вполне очевидным, потому что в рукописи много направлений текста и взаимоналожений его фрагментов, а в транскрипции, конечно, можно что-то печатать вертикально или по диагонали, но всё равно соответствие получается не полным. Во-вторых, при таком формально схематичном соответствии теряется возможность связного, осмысленного прочтения текста.
Поэтому транскрипция была заменена послойным чтением рукописи, которое ввели текстологи 1920-х годов, — Б. В. Томашевский, С. М. Бонди и другие. Здесь всё хорошо, но имеется как минимум два минуса. Первый минус: часть этих прочтений неизбежно гипотетична, а отделять гипотетическое от фактического либо нет технической возможности, либо это крайне усложнит «читабельность». Второй минус — полное отсутствие визуального соответствия между текстом и рукописью. В послойной расшифровке мы видим, что наш предшественник-текстолог читал это место так-то и так-то; но какие именно фрагменты текста соответствуют тем или иным местам в печатном издании, мы не знаем — каждый раз приходится догадываться, и не всегда это возможно. После того как текстологи объявили транскрипцию «подготовительными лесами» для послойного чтения и перестали ее печатать, у нас потерялась возможность проверить работу предшественников, уточнить ее и предложить альтернативу, не наступая на те же грабли и не изобретая велосипеда.
И вот теперь все эти альтернативы — делать ли факсимиле рукописи, давать ли транскрипцию или послойное чтение, разделять ли несомненное чтение и гипотетическое — начинает снимать электронная текстология. Мы можем давать несколько параллельных текстов: два, пять, десять — сколько угодно. Можно выводить на экран списки разночтений. В общем, исходные данные и результаты их анализа могут быть представлены одновременно.
Важно, что множественное представление текста становится не просто удобным инструментом визуализации, а дает уже совершенно новое понимание текста. Моделируется то, что французская «генетическая критика» называет авантекстом — т. е. тот многослойный, разнонаправленный, нелинейный текстовый процесс, который протекает за кажущейся «окончательностью» дефинитивной редакции. А следя за авантекстом, представленным динамически (хронологически), мы увидим «роение» будущего текста в черновиках, увидим, что какие-то направления в его развитии «отсыхают» и отваливаются, другие, напротив, побеждают, а часть будет перенесена потом в другие черновики других произведений.
Вот, например, черновик первой редакции стихотворения Пушкина «На холмах Грузии лежит ночная мгла…» в так называемой Первой арзрумской тетради (мы можем теперь знакомиться с ней по упоминавшемуся факсимильному изданию). Текст датирован 15 мая (1829 года):

Работу Пушкина над стихотворением в свое время подробно описал С. М. Бонди [23].
Сначала поэт записал первую строфу:
Все тихо — на Кавказъ ночная тѣнь легла
Мерцаютъ звѣзды надо мною
Мнѣ грустно и легко — печаль моя свѣтла
Печаль моя полна тобою.
После этого, через череду многочисленных правок, поэт пришел к такому тексту:
Все тихо. На Кавказъ идетъ ночная мгла.
Восходятъ звѣзды надо мною.
Мнѣ грустно и легко. Печаль моя свѣтла;
Печаль моя полна тобою.
Тобой, одной тобой. Унынья моего
Ничто не мучитъ, не тревожитъ,
И сердце вновь горитъ и любитъ — оттого
Что не любить оно не можетъ.
Прошли за днями дни. Сокрылось много лѣтъ.
Гдѣ вы, безцѣнныя созданья?
Иныя далеко, иныхъ ужъ въ мірѣ нѣтъ —
Со мной одни воспоминанья.
Я твой по-прежнему, тебя люблю я вновь.
И безъ надеждъ, и безъ желаній,
Какъ пламень жертвенный, чиста моя любовь
И нѣжность дѣвственныхъ мечтаній.
Затем на обороте этого же листа Пушкин попробовал продолжить стихотворение, однако отбросил продолжение, даже не завершив его:
И чувствую, душа въ сей <нрзб> [24] часъ
Твоей любви, тебя достойна
Зачѣмъ-же не всегда …………………….
Чиста, печальна и спокойна.
После этого Пушкин вычеркнул третью строфу, специальными пометами исключил вторую и восстановил первоначальное чтение первой. Получилось:
Все тихо — на Кавказъ ночная тѣнь легла.
Мерцаютъ звѣзды надо мною.
Мнѣ грустно и легко — печаль моя свѣтла,
Печаль моя полна тобою.
Я твой по-прежнему, тебя люблю я вновь.
И безъ надеждъ, и безъ желаній,
Какъ пламень жертвенный, чиста моя любовь
И нѣжность дѣвственныхъ мечтаній.
Между прочим, Бонди считал, что «этот вариант не уступает» окончательному «в художественном отношении». Только в следующем, беловом автографе Пушкин перенес действие в Грузию: «На холмы Грузии ночная тень легла», затем ««На холмах Грузии лежит ночная мгла». Но еще год спустя он еще не был уверен в строке «Шумит Арагва предо мною»: в автографе из собрания А. Я. Полонского (Париж), датируемом серединой 1830 года, это стих вписан и затем зачеркнут [25].

В остальном это — уже почти тот самый, хорошо нам знакомый окончательный текст, только в 5-й строке — «мечтанья», а не «унынья»:
На холмахъ Грузіи лежитъ ночная мгла
[Шумитъ Арагва предо мною]
Блистаютъ звѣзды надо мною —
Мнѣ грустно и легко, печаль моя свѣтла<,>
Печаль моя полна тобою,
Тобой, одной тобой… мечтанья моего
Ничто не мучитъ, не тревожитъ
И сердце вновь горитъ и любитъ — отъ того
Что не любить оно не можетъ.
Эти процессы могут быть зафиксированы с гораздо большей полнотой и адекватностью, чем раньше.
— Какие дополнительные опции, какой спектр задач по отношению к оцифрованным рукописным материалам вы видите?
— Максимально насыщенный связями гипертекст и семантизация этого гипертекста.
— Как этого добиться?
— Во-первых, изображения должны быть корректно идентифицированы. Должно быть понятно, каким объектам архивного хранения они соответствуют. Во-вторых, нужно объединить данные разных хранилищ, чтобы можно было автоматически производить «data harvesting» — «сбор данных». Эта задача постепенно решается, и обмен архивно-библиотечными данными идет, но все-таки окончательно она не решена, т. е. мы не умеем проводить поиски сразу по всем архивам или библиотекам одной страны или одной отрасли знаний.
Описания в разных архивах и библиотеках не совпадают по своему формату. И нам нужно сделать так, чтобы они совпадали или, по крайней мере, происходил автоматический перевод из одного формата в другой. Если эти проблемы игнорировать, то получится большая свалка неидентифицированных информационных объектов, как это произошло с коллекцией Google Books. Там до сих пор нет корректных унифицированных описаний книг, потому что исходные описания не опирались на данные библиографических карточек. Но даже потом, когда нужную информацию стали использовать, оказалось, что эти описания построены по разным правилам. Если в Google Books оцифровано три экземпляра, то по одному описанию вы, может быть, найдете один, а два других уже не найдете, сопоставить их вам не удастся. А может быть, и ни одного не найдете, если ваше описание не конгруэнтно ни одному их этих трех. Сравним это с копиями тех же самых книг из американских библиотек в Hathi Trust (но только американских, потому что книги из европейских библиотек туда не попали): там видно, что для идентификации книг использованы существующие библиотечные каталоги и поэтому гораздо меньше такого безобразия, как в Google Books.
Мораль: если не заниматься проблемами идентификации, то получится, что у вас всего очень много, а найти ничего нельзя. Электронные копии появились, а вы их не можете разыскать, поскольку не можете выяснить, существуют они или нет, а значит, их как бы и не существует.
— Распространяется ли эта ситуация на рукописный архив?
— Идентификация данных и автоматизированный обмен данными — важнейшая задача. Но мне хотелось бы повторить: очень многие препоны на пути к новым формам представления знания носят не технический и не интеллектуальный характер, а характер чисто поведенческий и юридический. Косность существующих институций, законов, установлений, да и просто привычек мешает — даже не человеку, а человечеству — двигаться вперед.
— Можно ли повлиять на ситуацию?
— Я не стал бы вслед за киберкоммунистами утверждать, что информация «хочет быть свободной». Но информация, несомненно, должна распространятся свободно — по крайней мере, к этому следует стремиться. Человечество должно изыскать для этого средства. А если прогресс — это «прогресс в осознании свободы», как учил Гегель, то, соответственно, и осознание того, что информация свободна, должно прийти на смену идее о том, что информация, подобно вещи или рабу, обязательно кому-то принадлежит, что она может быть заперта и строго охраняема, а за «незаконное» пользование ею нужно наказывать. Я думаю, что лет через сто, когда любители истории будут читать о том, как у нас сажали в тюрьму на десятки лет людей за то, что они прочли книгу или статью или прослушали музыкальное произведение, это будет казаться таким же диким, как нам кажутся дикими явления прошлого, основанные на предрассудках, давно уже с тех пор отвергнутых. Ну, что-то вроде охоты на ведьм.
Публикация подготовлена при поддержке РНФ. Проект № 19-18-00353, НИУ ВШЭ
-
- rvb.ru
- lib.ru, az.lib.ru
- feb-web.ru
- imli.ru
- otipl.philol.msu.ru/~imk
- cpcl.feb-web.ru
- Вера Полилова, Игорь Пильщиков. Цифровое будущее мировой литературы // ТрВ–Наука. № 294 от 24 декабря 2019 года.
- gutenberg.org
- gallica.bnf.fr
- catalogue.bnf.fr
- nlr.ru
- rsl.ru
- hum.hse.ru/digital/news/434038749.html
- dostoevskyarchive.pushdom.ru
- Баршт К. А., Райхель Б. С., Соколова Т. С. О методе цифровой спектрофотометрии в изучении рукописи писателя (на примере «Сибирской тетради» Ф. М. Достоевского) // Изв. РАН. Сер. лит. и яз. 2012. Т. 71. № 4.
- mandelstam.hse.ru/archive
- ivanov—rgali.ru
- trv—science.ru/2020/08/otkrytomu—dostupu—rad—i—ya—i—moj—apparat/
- hathitrust.org
- library.columbia.edu/libraries/rbml/services.html
- library.harvard.edu/services-tools/scan-deliver
- library.harvard.edu/digital-collections
- Бонди С. М. Черновики Пушкина. М., 1978. С. 11–25.
- Желающие могут попытаться прочесть неразобранное слово самостоятельно.
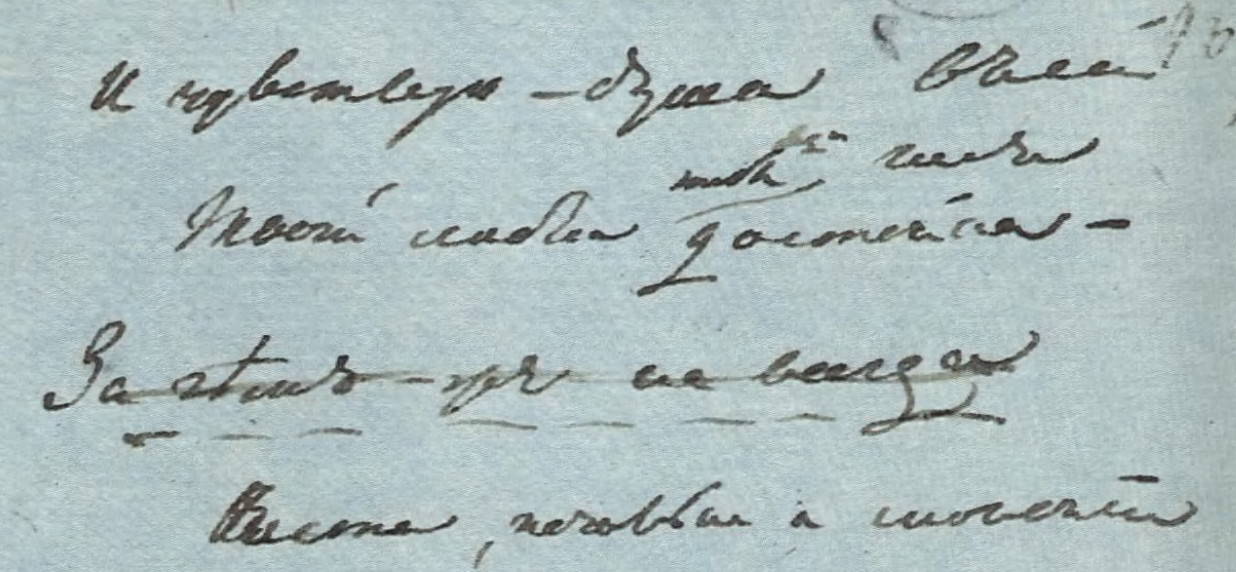
- Алексеев М. П. Новый автограф стихотворения Пушкина «На холмах Грузии» // Временник Пушкинской комиссии, 1963. Л., 1966. С. 34.
1 См. также заметку Виталия Мацарского «Открытому доступу только рад — рад и я, и мой аппарат» [18]. — Ред.

 (2 оценок, среднее: 4,50 из 5)
(2 оценок, среднее: 4,50 из 5)
Спасибо, очень интересно!»
«Внешними поисковыми системами (Google, «Яндекс») эти коллекции не индексируются»
– это крайне широко распространённая ситуация с электронными библиотеками, по не понятной мне причине очень часто в robots.txt сайтов электронных библиотек запрещается индексация большей части содержимого. До недавнего времени и elibrary не индексировался googl’ом»
«Существующая система копирайта принципиально устарела в момент появления Интернета, а сейчас, когда число текстов, распространяемых в электронной среде, существенно превзошло число всех прочих текстов, она устарела катастрофически, и предпринимаются серьезные попытки ее изменить… менять всё нужно радикально, ведь в принципе изменились соотношения между оригиналом и копией, между чтением и копированием, так что существующая система — просто бревно на пути прогресса»
— Несомненно. Мне представляется, что надо подготовить и обосновать конкретные предложения по изменению копирайта для начала для научных публикаций, заручившись поддержкой библиотек, научного сообщества, РАН и т.д. Например, можно предложить уменьшить срок копирайта для научных публикаций с чудовищных 70 лет после смерти автора до 1-2 лет после выхода в свет. Сейчас довольно много журналов придерживается подобной модели, когда свежие статьи доступны по подписке, а по истечении некоторого времени (1-2 года) попадают в открытый доступ.
Мне кажется, 1-2 года это, все же перебор. Можно воспользоваться длительным опытом системы технического патентования, где срок действия патента составляет от 5 до 25 лет, кроме того, обладатель патента должен оплатить пошлину за защиту своих прав. Но 70 лет после смерти автора — это, действительно, полный абсурд.
Но патентование это совершенно другой механизм, чем публикация статей. И цели и средства, и вообще кроме текста на бумаге, ничего общего. Суть патентования в исключительном праве на использование ИС, но сами патенты доступны бесплатно сразу, даже раньше, с подачи заявки аннотация уже есть в доступе. Их можно без ограничений использовать в научной или учебной деятельности, не нарушающей исключительные права владельца.
Поэтому 1-2 года задержки что бы просто прочитать статью, без каких-то явных выгод, звучит вполне разумно.
Общее между патентом и авторским правом — то, что и то и другое — формы защиты интеллектуальной собственности. Кроме того, авторское право (и смежные права) тоже не ограничивают возможность использования произведения, т.е. чтения (просмотра, прослушивания и т.д.) а ограничивают только возможность копирования. Так что читать статью, так же, как и патент, вы имеете право сразу же, после ее публикации.
Кроме того, мне кажется логичным, что для того, чтобы защитить свои имущественные права (а не авторские, которые неотчуждаемы и не носят имущественного характера) нужно зарегистрировать объект права в государственном органе и оплатить расходы на его защиту. Это сразу заставляет подумать — а стоит ли этим заниматься.